To Evolutionary Computation and Beyond
artificial intelligence evolutionary computation
El conocimiento científico se caracteríza por la sistematización del proceso de aprendizaje y la verificicación de sus resultados. En particular, los enfoques "Buttom-up" y "Top-down" distinguen dos tipos de aprendizaje.
— Bottom-up processing […] refers to processes that take a lower-level representation as input and create or modify a “higher-level” representation as output. Top-down processing […] refers to processes that operate in the opposite direction, taking a “higher-level” representation as input and producing or modifying a lower-level representation as output. — Palmer, 1999
El enfoque Top-down parte de una teoría o conocimiento bien establecido del fenómeno, seguido de un proceso de interpretación y descomposición en problemas menos complejos (divide y vencerás). El enfoque Buttom-up parte de la observación y generación de hipótesis del fenónemo, seguido de un proceso de verificación y formulación de la teoría.
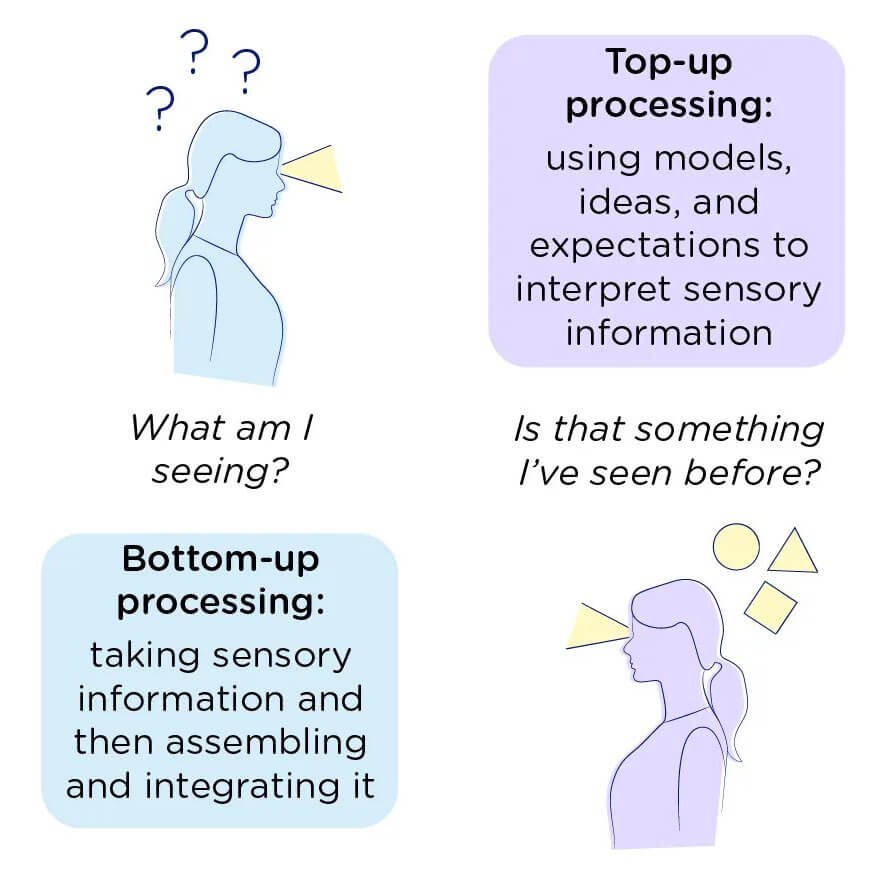 Esquema de ambos enfoques.
Esquema de ambos enfoques.
En la IA el enfoque Top-down permite emular el comportamiento inteligente al resolver tareas humanas mediante la descomposición de los problemas en algoritmos computacionales de menor complejidad. El enfoque Buttom-up, por otro lado, buscar hacer emerger el comportamiento inteligente necesario para resolver tareas complejas mediante algoritmos que emplean mecanismos de adaptación.
El término “cómputo inteligente” (CI) se usa en ciencias computacionales para referirse a aquellos algoritmos con capacidades adaptativas relacionadas con la inteligencia.
— El cómputo inteligente es el estudio de mecanismos adaptativos para generar o facilitar el comportamiento inteligente en ambientes complejos, inciertos y cambientes. — …
Los paradigmas del CI son:
- Redes neuronales
- Algoritmos evolutivos
- Inteligencia colectiva
- Sistemas inmunes artificiales
- Sistemas difusos
Sobre el inicio
Inicialmente, el área surge de una idea propuesta en 1939, cuando Wright establece una relación entre un sistema evolutivo y un modelo matemático. Más tarde, Friedman (1956) y Friedberg (1959) proponen modelos computacionales inspirados en esta clase de sistemas.
Sin embargo, el actualmente conocido como Cómputo Evolutivo (CE) atravesó cuatro periodos importantes durante los años 60 y 90.
Inicialmente, el área fue impulsada por tres grupos de investigación durante los años 60 (los catalíticos):
-
El grupo de Lawrence Jerome Fogel en la Universidad de California.
-
El grupo de Ingo Rechenberg y Hans-Paul Schwefel en la Universidad Técnica de Berlín.
-
El grupo de John Hanry Holland en la Universidad de Michigan.
Durante los años 70 (los explorativos) y de la mano de los grupos anteriores se consolidaron los siguientes paradigmas:
-
La programación evolutiva
-
Las estrategias evolutivas
-
Los algoritmos genéticos
Seguido de esto, durante los años 80 (los explotativos) se diversificaron las aplicaciones del CE y se desarrollaron variantes especializadas como la programación genética y la evolución diferencial, además, surgieron los primeros congresos. Mas tarde, durante los años 90 (los unificadores) se consolida el área del CE y surge el primer journal especializado.
Actualmente el CE se emplea para resolver problemas de búsqueda u optimización que sean difíciles de replicar experimentalmente o que no sea plausible resolverlos mediante una búsqueda exahustiva.
Sobre la computación evolutiva
Un algoritmo evolutivo es un modelo computacional basado en el proceso de evolución y el principio de supervivencia del más apto. Se compone escencialmente de los siguientes seis elementos:
- Representación de soluciones
- Función de aptitud
- Población de soluciones
- Selección de padres
- Operadores de variación
- Mecanismo de reemplazo
Estos elementos integran un proceso iterativo de adaptación.
Algoritmos genéticos
Para emplear dicho paradigma se debe escoger una representación de soluciones, ya sea del tipo binaria, entera, real o mediante permutaciones. Después, se debe seleccionar uno de los siguientes operadores de mutación.
-
Mutación simple: se altera un bit (flip) de información.
-
Mutación uniforme: se aplica la mutación simple a n-bits, ya sea mediante el flip (caso binario) o mediante una distribución de probabilidad uniforme (caso real).
-
Mutación por readenamiento: se selecciona una subcadena de bits y se desplaza a otro extremo de la cadena.
Además, se debe seleccionar un operador de cruza, para ello se denomina punto de cruza a la separación entre los bits de una cadena. Los operados disponibles tienen aridad dos y son los siguientes.
-
Cruza uniforme: se construye el cromosoma hijo a partir de la selección aleatoriamente uniforme de uno de los genes de los padres.
-
Cruza intermedia: se genera un coeficiente a, se selecciona un punto de cruza k y apartir de los padres ordenados se aplica una ecuación de cruza.
-
Cruza aritmética simple: se aplica la ecuación de cruza anterior, se selecciona un punto de cruza y se calcula el coeficiente a en función de los límites de las variables.
-
Cruza aritmética completa: se aplica la cruza aritmética simple todos los genes del cromosoma.